Find Everything: A General Vision Language Model Approach to Multi-Object Search
|
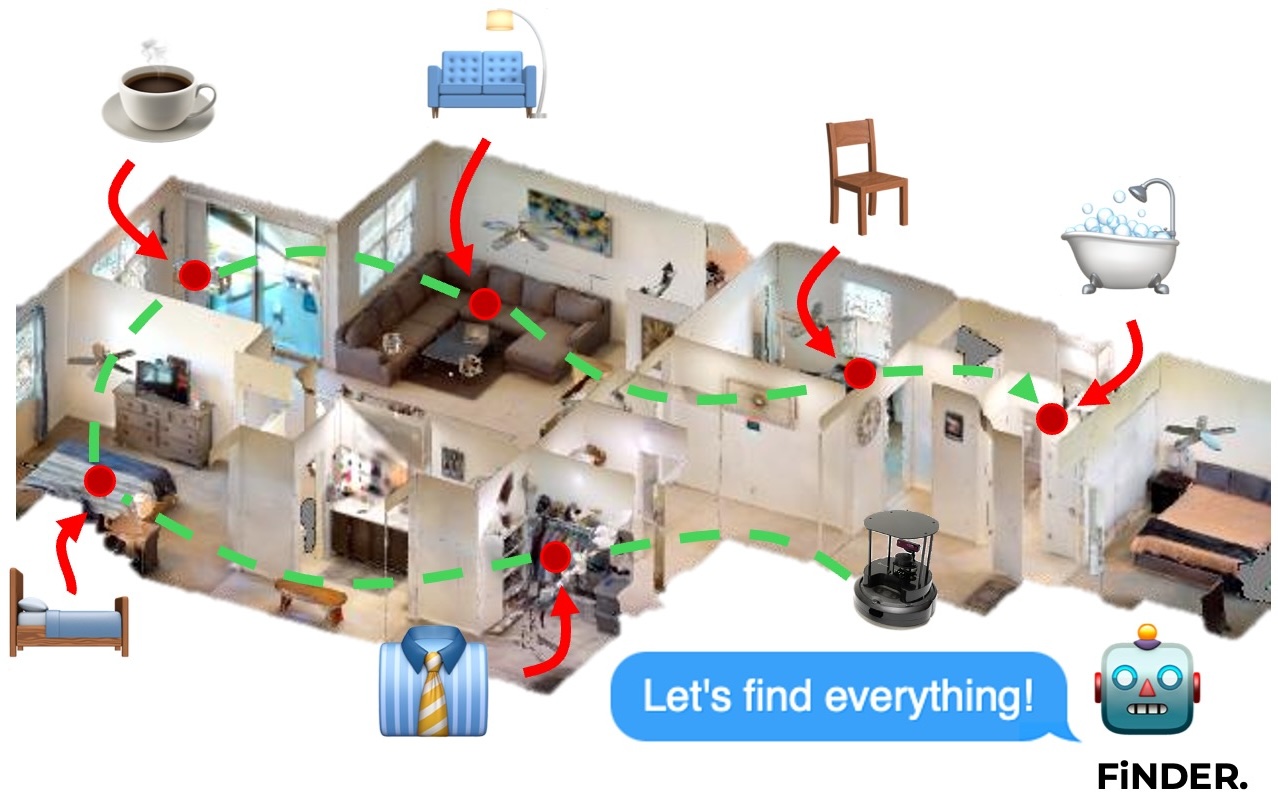
Efficient navigation and search in unknown environments for multiple objects is a fundamental challenge in robotics, particularly in applications such as warehouse automation, domestic assistance, and search-and-rescue. The Multi-Object Search (MOS) problem involves finding an optimal sequence of locations to maximize the probability of discovering target objects while minimizing travel costs. In this paper, we introduce a novel approach to the MOS problem, called Finder, which leverages vision language models (VLM) to locate multiple objects across diverse environments. Specifically, our approach combines semantic mapping with spatio-probabilistic reasoning and adaptive planning. We enhance object recognition and scene understanding through the integration of VLM, constructing an episodic semantic map to guide efficient exploration based on multiple object goals. Our extensive experiments in both simulated and real-world environments demonstrate Finder's superior performance compared to existing multi-object search methods using deep reinforcement learning and VLM. Additional ablation and scalability studies highlight the importance of our design choices in addressing the inherent uncertainty and complexity of the MOS problem.
The Finder Architecture
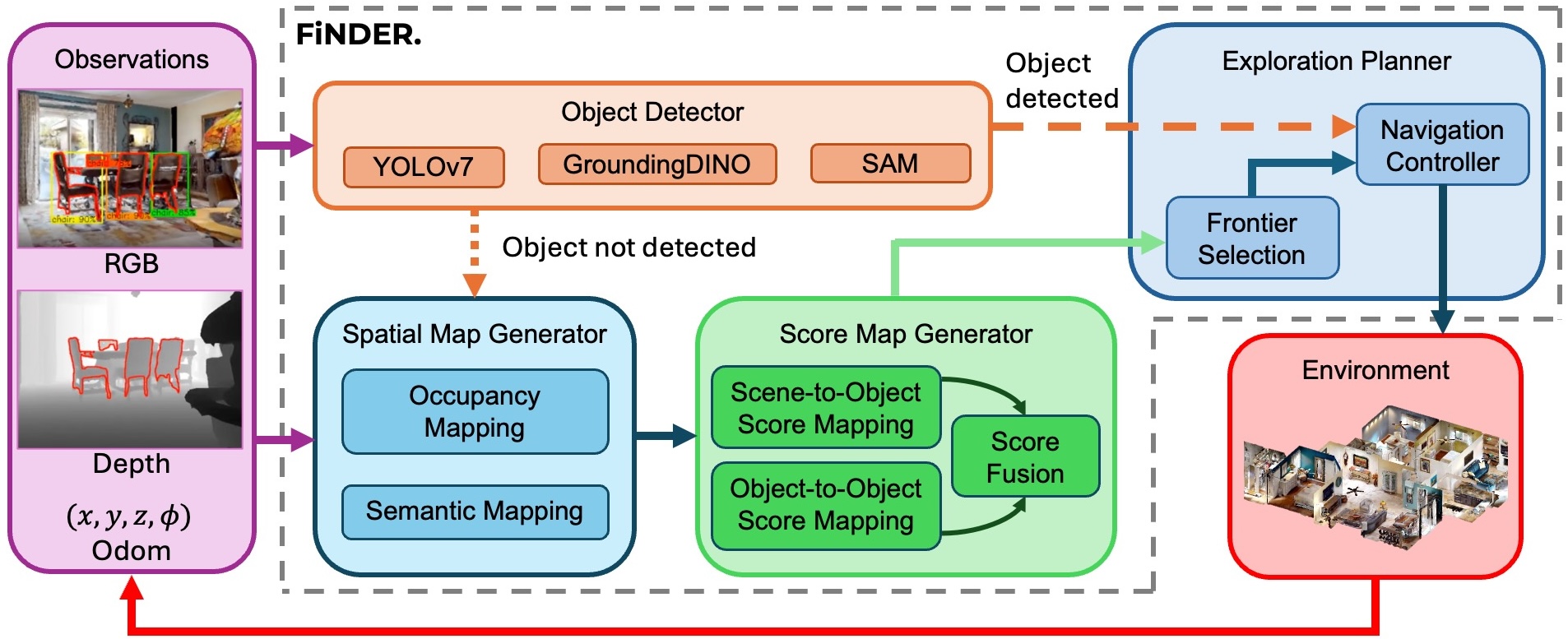
The proposed model, Finder, consists of four core modules: Object Detector, Spatial Map Generator, Score Map Generator, and Exploration Planner. The Object Detector identifies scene and target objects using YOLOv7 and Grounding-DINO, generating segmentation masks and determining the closest points in 3D space. The Spatial Map Generator creates occupancy and semantic maps from RGB and depth images to represent the environment. The Score Map Generator computes scene-to-object and object-to-object correlation scores, fusing them into a unified score map that guides exploration. The Exploration Planner selects frontiers based on utility scores, combining correlation scores and distance to unexplored areas, and navigates the robot using A* and Timed Elastic Band planners. This approach efficiently tracks and reasons about multiple objects in complex environments.
Experiment Video
Acknowledgements
This work was supported by Syncere AI.
Website template from here.
|